
Understanding the Imaging Data
SDSS has imaged about one-third of the night sky in five broad bands (ugriz). The resulting catalog includes photometry for almost half a billion unique objects. Understanding how to use SDSS imaging data requires some knowledge of how the data were collected. This page explains what you need to know about SDSS imaging data.
Describing SDSS images
The SDSS imaging camera scanned the sky in strips along great circles. Each strip consists of six parallel scanlines, 13 arcmin wide, with gaps of about the same width. Thus two strips, offset slightly from each other, together make a single stripe 2.5 degrees wide. Each scanline includes data in all five filters, ugriz. The fundamental units of SDSS images are fields into which the scanlines are divided (with some overlap). Each is 10 by 13 arcminutes, corresponding to 2048 by 1489 pixels. Each field can be uniquely identified by a sequence of three numbers:
- the run number, which identifies the specific scan,
- the camera column, or “camcol,” a number from 1 to 6, identifying the scanline within the run, and
- the field number. The field number typically starts at 11 (after an initial rampup time), and can be as large as 800 for particularly long runs.

For example, this image shows a single SDSS field (gri color composite). You can search for this area of sky by its RA and Dec position in the SkyServer Navigate tool, but to understand when and under what conditions this image was taken, it helps to know the field’s run-camcol-field identifier. Using those numbers, you can search for more information about this field in the CAS “Field” table. An additional number, rerun, specifies how the image was processed. The run-camcol-field identifier can also be useful to download the FITS files for each SDSS filter, in this case, 3704-3-91. Entering that identifier into the Science Archive Server Imaging Fields search will create links to download the individual filter images as FITS files.
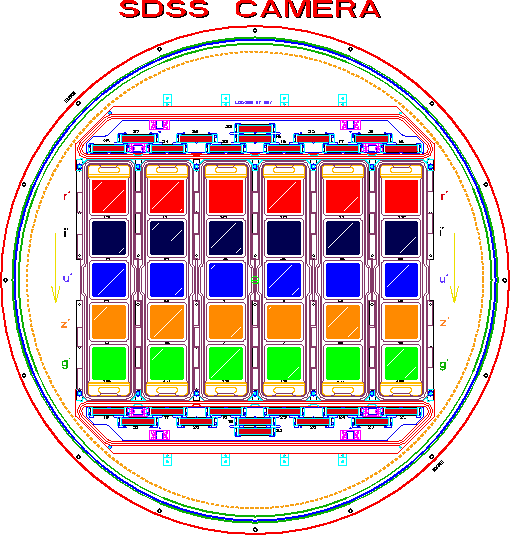
The SDSS camera worked in drift scan mode, opening its shutter for extended periods and imaging a continuous strip of the sky. This figure illustrates the focal plane of the SDSS camera. In the coordinate system shown there, the sky drifts downwards. Each continuous drift scan is referred to as a run and there is a unique integer identifying the run. For science quality runs, the lowest run number is 94, and the highest is 8162.
The SDSS camera had six parallel camera columns, meaning that each run is divided into six parallel scanlines, one for each camera column. These images are known as camcols, and are numbered 1 through 6. Each camcol is 2048 pixels wide (the width of the CCDs). There is a 11.7 arcmin gap between camcols; usually, the gap between camcols in a run is filled in by images from another drift scanning run that slightly overlaps in sky coverage.

Each camcol is artificially broken up into a series of overlapping fields, each 1489 pixels long (2048 pixels wide). Each field overlaps by 128 pixels with adjacent fields, to ensure that objects are not misdetected due to being too close to the edge of a field. Fields are the basic unit of analysis input into the SDSS imaging pipeline.
Finally, there have been multiple reprocessings of the data over the years. Each reprocessing has been denoted by an integer (the first being rerun 0, the latest being rerun 301). Each rerun consists only in a change to the photometric pipeline, not to the underlying data.
This figure shows the overall result for a small section of one run in the SDSS. There are six continuous camcols, broken up into fields. Each image is uniquely identified by its run, camcol, field and rerun number. You can explore the JPG images of a run to get a sense of the geometry.
Filters
In the camera schematic above, note that there are five rows of CCDs, labeled u, g, r, i and z. The SDSS camera has five filters, which together span the optical window. Each filter images a section of sky nearly, but not exactly, simultaneously (each filter is separated by 71.72 seconds). The filters always observe in the same time sequence: r, i, u, z and then g. A mnemonic for remembering the order is “robert is under ze gunn.”
The multiple bands allow a determination of the colors of detected objects. For example, in the JPGs shown above are a composite of the g, r, and i images. In the catalog data returned by SkyServer and CasJobs, all imaging parameters associated with a given bandpass are named accordingly (e.g., the Petrosian flux in the u band is named petroflux_u; in the g band it is named petroflux_g, etc.). In the flat-file (FITS) versions of the catalog data returned by the DR13 Science Archive Server, the bandpasses are given in order of increasing wavelength, ugriz. Additionally, note that the time gap between filters means that the images of moving objects (i.e., asteroids) are offset slightly between successive filters. We have used this to put together a comprehensive catalog of asteroids found in SDSS, the SDSS Moving Object Catalog.
Object ID numbers, deblending and resolving

Going from pixels on the camera to a robust catalog of sky objects is a long and complicated process. The entire process is explained in the Imaging Pipeline and Algorithms pages. The result is a set of objects within each field, which each get a unique identifier within the field known as “obj” in CAS, and as “id” in the flat files. Thus, each catalog object has a unique combination of run-camcol-field-id-rerun; this combination is hashed into a single 64-bit integer called ObjID. Note that between different photometric reduction versions (e.g., between DR7 and DR8) the rerun value, the id, and the objid all change for each object.
Using the SDSS imaging catalogs requires understanding two important processes: deblending and resolving.
First, the imaging pipeline detects objects in the images by flagging contiguous regions of pixels with a signal exceeding the sky background. These contiguous regions often actually contain multiple astronomical sources, and are thus known as parent objects. This figure shows a single parent object. Each parent has its properties measured and is tracked into the final catalog, but it is not usually recommended for the user to use them, and they are never considered “primary” detections. A process called deblending breaks each parent up into individual, distinct astronomical sources, known as the “child” objects. For example, in the image to the right, the yellow diamond is the “center” of the parent, and the red diamonds mark the child objects. For nearly all purposes, analyses of the catalog data should use the children.
Second, there is some overlap between fields within each run, as well as between different runs. Because of these overlaps, any source on the sky can in principle be deblended as a child detection on several different runs. The imaging pipeline’s resolve procedure determines the “best” observation of every object, which it identifies as the primary object. The documentation on the Resolve Algorithm describes how resolve chooses which observation to define as the primary object. For most purposes, users want primary objects, which can be identified using the RESOLVE_STATUS bitmask or by search for objects with mode set to 1.
Finally, not all objects are “good” even when they are unique. Many objects, for various reasons, have less-than-perfect photometry. Data describing the image quality associated with each catalog object is stored in the parameters FLAGS1 and FLAGS2 (in CAS and SkyServer, these are combined into a single 64-bit FLAGS bitmask). Some examples of imaging quality flags are those associated with saturated pixels (SATURATED), objects too close to the edge of a field (EDGE), or objects that are possible misclassified cosmic rays (MAYBE_CR). These flags are stored as bitmasks. To learn how to use them to find reliable imaging, see the Clean Photometry tutorial and look at our photometric catalog recommendations. A shortcut is to use the clean flag in the photometric catalog, which is 1 for “clean” data and 0 otherwise; however, we recommend that users evaluate whether this flag is being overly (or underly) restrictive for their particular use cases.


